

Компьютерное зрение на службе у истории: как отечественные технологии ИИ помогают историкам в работе
Технологии искусственного интеллекта (ИИ) прочно закрепились в нашей жизни. Так или иначе, но все мы сталкивались с различными системами ИИ: чат-боты, автоответчики, реклама в соцсетях, генерация изображений и видео, распознавание объектов через приложения на смартфоне, голосовые помощники в умных колонках, автопилот в автомобилях, и даже иллюстрация к этой статье сгенерирована ИИ. Но кроме бытового применения, технологии ИИ очень нужны науке и научным работникам. Они берут на себя рутинные задачи, освобождая время специалистов-людей для более важных проектов.
Сегодня поговорим, как одна из таких технологий ИИ — компьютерное зрение — помогает российским историкам и археологам восстанавливать и быстро расшифровывать древние тексты на различных языках.

Что такое компьютерное зрение
Искусственный интеллект (ИИ) — это не просто отдельная технология, это целое научное направление, специалисты которого занимаются разработкой систем для выполнения сложных задач аналогично тому, как бы выполнил ее человек. ИИ приходит тогда, когда задачу уже невозможно сделать с использованием классических алгоритмов.
Под компьютерным зрением подразумевают технологии и системы ИИ, способные самостоятельно распознавать нужные объекты на изображениях или видеозаписях. Это может быть как отдельное приложение и сервис, куда вы просто загружаете нужный файл или видео (приложение с умной камерой на телефоне или онлайн-сервис), так и целый программно-аппаратный комплекс, который собирает визуальные данные и передает их в собственный или удаленный центр обработки данных для дальнейшего распознавания нужных объектов системой. Примером такого комплекса может быть робот, проверяющий качество урожая или состояние растений в полях.
Принцип действия таких технологий простой: система получает фото или видео, анализирует и пытается обнаружить объекты, на поиск которых запрограммировал ее специалист-человек. Система, учитывая имеющиеся у нее данные, делает предположение, что на изображении или видео именно тот объект, о котором она думает. Но такой простоте предшествует продолжительный и тяжелый период обучения. Чтобы система ИИ правильно понимала и не путала объекты, ей нужно как можно больше корректных обучающих данных: фото и видео, на которых специалисты-люди вручную делают разметку. Нередко для повышения качества данных привлекают не технических, а профильных специалистов: зоологов для разметки фото и видео со зверями, геологов для определения тех или иных пород, энтомологов для определения насекомых и так далее.
Тут как с детьми. Родителям необходимо много раз показать ребенку карточку с красным цветом и периодически проводить «экзамен» чтобы ребенок запомнил, что такое «красный» и чем он отличается от других цветов. Условно, следующий уровень — учить детей отличать красные яблоки от зеленых, а потом и более сложные объекты, оттенки красного и так далее. С системами компьютерного зрения, как и с детьми, нужно быть терпеливыми и аккуратными, а также внимательно следить, чтобы вводные данные были без ошибок. Иначе система будет выдавать неправильный результат. Ведь вы ее так научили.
Каждый раз, когда ваша умная камера определяет сорт яблока, вид объекта или просто накладывает фильтр в TikTik, помните — за этой уже привычной нам функциональностью скрываются десятки часов работы по разметке данных специалистами-людьми для систем ИИ. При создании озвученных далее систем работали не только ИТ-специалисты, но и ученые-историки и лингвисты, участвовавшие в обучении и контроле работы ИИ.
Отечественное компьютерное зрение на службе у истории
«Поиск по архивам»
В начале 2023 года в России стартовал проект «Поиск по архивам», открывающий всем желающим доступ к огромной базе страниц исторических документов с текстовой расшифровкой. В рамках проекта система компьютерного зрения, разработанная компанией Яндекс, обрабатывает рукописные документы, датируемые от середины XVIII до начала ХХ века, и распознает на них текст, учитывая как особенности изменения русского языка за указанный период, так и почерк, синтаксис, смысл текста и не только. Такая расшифровка существенно облегчает поиск нужных данных по архивным документам.

Помните, мы говорили, что за любым подобным проектом кроется кропотливая работа специалистов людей? Для обучения системы специалистами Яндекса было вручную подготовлено 2000 рукописных документов. Расшифровщикам нужно было при разметке учитывать огромный список нюансов, которые нам могут показаться банальными, но не необученной системе ИИ.
Главной проблемой проекта стало распознавание строк. Человек мог писать так, что даже для читателей-людей непонятно, где начинается и кончается строка. Кроме того, даже в рамках одного и того же документа может быть разная длина и направление строки, на сканах документов просвечивался текст с другой страницы, буквы и слова обрывались, а смысл сказанного мог потеряться просто из-за того, что у разных писарей одни и те же буквы могли иметь разное значение. Для решения проблемы специалисты применили целый комплекс методов, начиная от индивидуального анализа каждого пикселя изображения и заканчивая группировкой в абзацы для упрощения работы.
Кроме того, исследователи обнаружили, что из-за схожести рукописного текста с узорами и иллюстрациями, которые могут присутствовать в книгах, ИИ находил текст там, где его нет, и даже составлял осмысленные предложения. Эта проблема была решена последующим дообучением системы, что лишний раз подтверждает ценность хороших обучающих данных.
Всего за год работы система расшифровала более 60 тысяч рукописных и печатных текстов — это более 10 млн страниц или 492 млн строк. На данный момент проект охватывает архивы 11 регионов, в том числе Москвы, Московской, Оренбургской, Новгородской, Иркутской, Астраханской и других областей.
«Рукописное наследие Древней Руси»
Еще одним знаковым отечественным проектом стал выпущенный в этом году программный комплекс, позволяющий производить поиск по текстам, созданным на рукописном старославянском языке. Над ним работали специалисты НИЯУ МИФИ и Института русского языка им. В.В. Виноградова. Система ИИ расшифровала 245 миней — церковнослужебных сборников, находящихся в архивах Российской государственной библиотеки, Исторического музея и региональных учреждений культуры.
В рамках проекта был создан сетевой ресурс «Рукописное наследие Древней Руси», куда любой желающий может зайти и поискать в базе нужную информацию. Процесс поиска не отличается от стандартной работы с поисковиками. Кроме того, при желании пользователь может использовать онлайн-клавиатуру для набора текста на старославянском языке.
При обучении нейросети проект столкнулся с не меньшими проблемами, чем специалисты Яндекса. Например, в старославянских рукописях одни и те же знаки также могли иметь совершенно разные значения. В частности, у одной и той же буквы может быть до 150 вариаций, поскольку каждый писец вносил в написание этих букв собственную стилистику. И это несмотря на то, что существовали уставы и каноны в отношении шрифтов и языка.
Сложности добавляют и исторические особенности. В частности, в XIV веке вышел Иерусалимский устав со своими нормами написания текстов. А в XVII это все переписывалось уже в рамках Никоновской книжной справы. Не все церковнослужители подчинялись новым нормам, продолжая писать на свой лад и критикуя представленные изменения.
Из-за этих сложностей система не может работать полностью самостоятельно. Из-за огромной вариативности работу ИИ требуется проверять человеку. Но в процессе такой проверки проводится дообучение системы. Ей показывают, где она ошиблась, добавляют верных данных и дорабатывают. В конце концов она сможет работать без участия специалиста-человека.
«Digital Петр»
В 2022 году Российское историческое общество, Санкт-Петербургский институт истории РАН и «Сбер» преподнесли подарок России к юбилею Петра I — проект «Digital Петр». «Сбер» задействовал собственные технологии компьютерного зрения для распознавания крайне сложного почерка Петра I, из-за которого расшифровка и публикация его работ сильно задерживается.

Если два предыдущих проекта учились работать со множеством разных авторов, то в данном случае все силы исследователей были направлены на расшифровку рукописей одного человека. Что, впрочем, проблем не уменьшило. Петр I также мог писать в разных направлениях, по разному писать те или иные буквы и использовать собственные слова и выражения, затрудняющие распознавание текста.
Поскольку на крайне сложно расшифровываемых рукописях одного человека не сформировать хорошую обучающую базу, исследователи использовали для первичного обучения модели письменные источники XVII-XVIII в.в.. И все равно пришлось очень постараться, чтобы соотнести полученный визуал с рукописями Петра I и установить истинное значение тех или иных слов.
Но труды команды были не напрасны. На текущий момент точность системы составляет 97,6%. На сайте «Digital Петр» вы можете ознакомиться с несколькими расшифрованными вариантами рукописей и при наличии даже загрузить свой файл.
Виртуальное разворачивание свитков
В этом году российские исследователи из компании Smart Engines и ФИЦ ИУ РАН представили совершенно новую систему ИИ для чтения свитков. Технология позволяет восстанавливать исторические тексты не разворачивая хрупкие исторические экспонаты. Это позволит работать с особо древними письменными источниками, пострадавшими вследствие естественного старения и неблагоприятных внешних факторов.
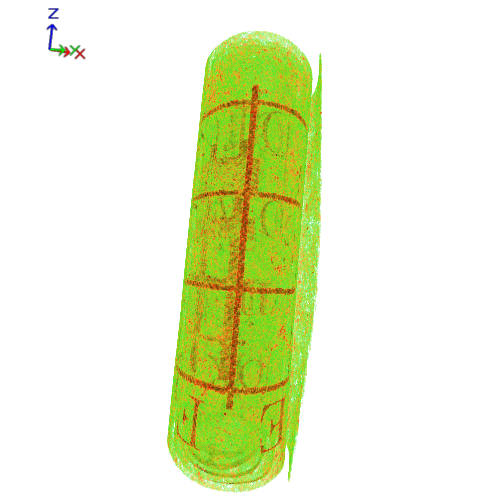
Технология сочетает в себе компьютерное зрение и методы рентгеновской томографии, абсолютно безопасные для хрупких снимков. Томограф позволяет определить содержимое свитков. Полученные данные обрабатывает ИИ, пытаясь понять, можно ли обнаруженные символы отнести к письменности или это артефакты, связанные с качеством бумаги или иного материала, на который нанесен текст. Система формирует цифровую копию документа, учитывающую послойность физического объекта исследования, и разворачивает его в виртуальном пространстве.
Идея использовать томограф для изучения хрупки экспонатов не нова. Но в рамках данного проекта исследователи решили проблему с автоматизацией процесса, снизив рутинную нагрузку на исследователей в части распознавания простых символов и артефактов. Активное участие человека требовалось только на этапе обучения системы.
Для обучения системы Smart Engines формировала собственный набор данных из шести образцов свернутых разными способами документов. На них специалисты нанесли буквы и цифры разного размера и схемы с различными графическими элементами. После они тренировали систему правильно распознавать, что написано на этих образцах.

В августе этого года в рамках The International Conference on Document Analysis and Recognition (ICDAR) – ведущей международной научной конференции в области анализа и распознавания документов — Smart Engines представит научную статью с результатами и подробностями исследования.
На текущем моменте развитии технологий компьютерного зрения человек не может полностью довериться экспертизе ИИ. Необходимо продолжительное дообучение систем, чтобы они работали как специалисты-люди или, желательно, еще лучше. Тем не менее уже сейчас, благодаря этим четырем проектам, российские исследователи получают время для более глубокого анализа древних текстов. Вместо того, чтобы с нуля садиться за исторический документ и вручную проводить первичный рутинный анализ, а после переносить его в компьютер, они могут взять в работу уже готовый расшифрованный и оцифрованный текст.
В перспективе такие системы, доступные всем исследователям, сэкономят десятки часов труда высококвалифицированных специалистов и станут главным драйвером развития отечественной науки.